从本文开始,我们进入 DAX 基础知识章节。Power BI 是由模型驱动的工具,合理的模型结构可以简化日后编写公式和维护报告的工作量,失败的模型结构会让一切变的复杂
为什么使用数据模型
在对 Power BI 的错误认识中,认为它是一个数据可视化工具的大有人在,实际上 Power BI 是一个基于数据模型的工具。 它使用独有的语言(DAX)在语义层(Semantic layer)定义度量值的业务逻辑,并允许使用两种语言查询数据模型:DAX 和 MDX,后者已经成为行业标准语言。
之所以选择 DAX 和 MDX,而不是更常见的 SQL,是因为 SQL 不适合用于语义层。 在企业 BI 工具的漫长历史中,即使工具生成 SQL 查询,也不可能在 SQL 中定义通用业务规则,除非是在数据源的行级别进行非常简单的计算。
例如,假设计算利润率%需要用到两张表, 在 SQL 中定义除以两个聚合结果的通用计算是一项复杂的任务。每个工具都发明了自己的方法来解决这一问题。 用 SQL 表示这种计算需要一个非常具体的查询,并且不具有足够的通用性,不能与同一查询中的任何筛选器、聚合或其他度量值的组合一起使用。
数据模型是什么
模型对于 Excel 用户和数据分析的新手可能是个比较陌生的概念,但我想大部分人应该都听说过以下这些模型:回归模型、分类模型、决策树模型、朴素贝叶斯模型。

算法模型示例
它们都属于算法模型的范畴,实现了 输入- 处理 – 输出 这样一个过程。算法模型用途广泛,但不是这里要讨论的内容,我们介绍的是另一种模型:数据模型,数据模型是现实世界的抽象,举个例子:超市昨天一共产生多少笔订单,每笔订单包含哪些商品,每种商品又由哪些原材料构成。我们把这些数据记录到表中,再导入数据库。这个时候你通过查询数据库就可以掌握超市的运营情况,单表可以视为结构简单的模型,通常我们研究的是基于多张表的模型,这时就引入了现实世界中的一个重要概念:关系。一旦表和表之间建立了关系,我们就摆脱了单表的束缚,可以在不同的表之间进行查询。你可以把关系想象成 Excel 中的 VLOOKUP,实际上关系要灵活和强大的多。
烂程序员关心的是代码,好程序员关心的是数据结构和他们之间的关系
— Linux 创始人 Torvalds

数据模型示意图
有哪些常用的数据模型
数据模型对于数据库使用者是一个很重要的概念,普通 BI 用户不必了解背后的所有内容,只需要掌握一些基本知识即可。
ER 模型(Entity Relationship Model)
实体关系模型,用实体加关系构成的数据模型描述企业业务架构,在范式理论上符合三范式,是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象,它更多是面向数据的整合和一致性治理,为基础数据仓库建设服务。
维度建模
星型模型和雪花模型都是维度建模中的常用模型,维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析,同时还有较好的大规模复杂查询的响应性能,更直接面向业务。
维度模型最基本的两个要素是事实表和维度表:
- 事实表:一般由两部分组成,维度和度量,通俗的理解为“某人在某个时间什么条件下做了什么事情”的事实记录,它拥有最大的数据量,储存了大部分定量数据,是业务流程的核心体现。
- 维度表:对事实表的补充说明,描述和还原事实发生时的场景,包含产品、人员、地点等定性数据,也包括时间数据(比如日期维度表)。 在星型架构中,最一致的表是日期维度表。 维度表包含用作唯一标识符的键列(一列或多列)以及描述性的列。
通常情况下,维度表包含的行数相对较少,更新频率较低。而事实数据表可能包含非常多的行,并且行数会随着时间的推移不断增长。
星型模型:事实表位于中心,维度表直接与事实表建立关系
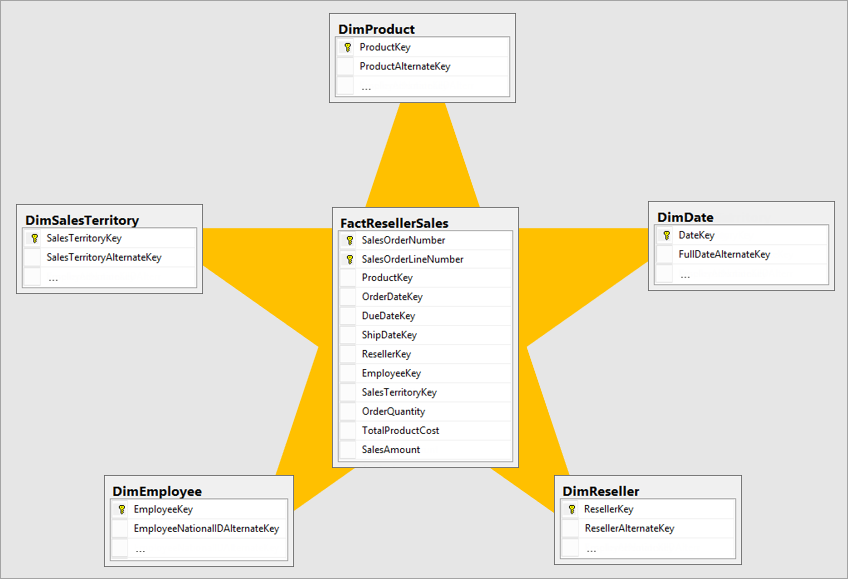
星型模型示意图(来自官方文档)
雪花模型:经过规范化存储的维度表,多张维度表连接在一起,单表没有冗余

雪花模型局部示意图(来自官方文档)
理解 Power BI 中的数据模型
DAX 是一种专门为计算数据模型中的商业逻辑而设计的语言。看完前面的介绍,你已经对数据模型有了一个初步的认识,如果你还不熟悉它,那么花些时间来介绍数据模型和关系是很有必要的,因为这些概念是你建立 DAX 知识的基石。
数据模型是一组通过关系连接到一起的表
我们都知道什么是表:一组包含数据的行,每一行被列分割,每列都有指定的数据类型,并且只包含一种信息。我们通常将表中的一行称为记录。表是管理数据的一种简便方法,表的本身已经是一个数据模型,尽管这是最简单的形式。因此,当你在 Excel 工作簿中填写名称和数字时,你正在创建一个数据模型。
Excel 智能表示例(来自官方文档)
如果数据模型包含许多表,通常它们是通过关系连接的。关系建立在两个表之间。当两个表通过关系连接在一起时,我们说它们是相关联的。从图形上看,关系由连接两个表的直线表示。图 1-1 显示了一个数据模型的示例。

由五张表组成的数据模型示意图
学习关系你需要了解的重要知识点:
- 关系中的两个表承担不同的角色,他们被称为关系的一端和多端。在图 1-1 中,注意 Product 表和 Product Subcategory 表之间的关系。一个子类别中包含许多产品,而单个产品只能有一个子类别。因此,Product Subcategory 表位于关系的“一”端(每行有一个子类),而 Product 位于“多”端(对应了很多产品)。
- 用于创建关系的列(通常在两个表中具有相同的名称)称为关系的键。在关系的一端,列的每一行需要有唯一的值。在关系的多端,相同的值通常在不同的行重复出现。如果列的每一行都是唯一值,则该列被称为表的键。通常情况下,表有一个列是键列。
- 关系可以形成链条。每个产品都有一个子类别,每个子类别都有一个类别。因此,每个产品都有一个类别。为了检索产品的类别,你需要遍历两个关系链。图 1-1 包含一个由三个关系组成的关系链的示例,从销售表开始,一直到产品类别表。
- 在每个关系中,可以有一个或两个小箭头。在上图中,你可以看到销售表和产品表之间的关系中有两个箭头,而其他所有关系都只有一个箭头,箭头表示关系将沿着此方向自动筛选。我们会在后面的文章中会更详细地讨论这个问题,因为确定正确的筛选方向是最重要的技能之一。
为什么说星型模型是 Power BI 的最佳模型结构
上文中我们提到了一个很重要的信息:星型模型是更适合 Power BI 建模使用的结构,这不仅是出于减少数据冗余的考虑,因为对于列式数据库来说,即使有一定的冗余也可以被引擎很好的压缩,更主要的原因是从计算准确性角度给出的建议。虽然宽表形式(所有的维度和指标都汇总到一张表)被很多 BI 工具或者分析系统采用,但是在 Power BI 中使用这种结构,在某些计算时可能导致异常结果。
使用宽表做数据源的报表可能计算出不准确的数字,而星型模型是一种更为可靠的分析系统
我用一个简单的例子来说明这个问题,在介绍自动匹配(Auto-Exists)的文章中,你将详细了解背后的原因。案例使用一张三行两列的表构造一个矩阵视图:

矩阵视图的度量值留空
定义如下两个度量值分别放入矩阵中,现在请你思考一下,它们各自会得到什么结果?
CountA = COUNTROWS('Table')
CountB = CALCULATE(COUNTROWS('Table'),'Table'[name]="TV")

两个度量值结果对比
CountA 计算表的行数,只对数据源存在的组合返回记录,所以类似<Apple,Electrical>这样的搭配属于无效组合,返回空值。CountB 度量值在前者基础上增加一个内部筛选器参数,将 name 值修改为 TV,根据 CALCULATE 计值流规则,这种写法无论外部上下文中的 name 列使用哪个值,都将被 CALCULATE 替换为 TV。如果你从这个角度思考,会发现右边的结果似乎并不正确,因为它只保留一行记录,如果替换发生,那么<Apple,Electrical>的组合将在内部被替换为<TV,Electrical>后返回 1,但结果并非如此。
不合理的模型结构带来的其他问题
单纯强调模型结构的重要性可能没法让你产生直观感受,这里我用反面案例来说明,一个糟糕的模型可能给你带来哪些问题,如果你过去习惯于在 Excel 里分析数据,那这部分内容是你需要特别关注的,很多使用者在切换到 Power BI 后,由于没有真正理解模型结构的重要性,在这上面走了很多弯路。
样例文件说明
DAX 圣经第一版案例使用官方的 Contoso 数据库,你可以从这里直接下载。书中的原理部分虽然没有提供示例文件,你可以使用下载的文件进行练习。
扩展阅读





关系的键:应该特指数据模型中发现直接关系的两张表中名称相同的列;表键应该是我们传统意义上的单表主键(单列或组合列);键列就是主键所在列;
这一段里的三个概念把我搞糊涂了,“关系的键”、“表的键”、“键列”。现在有些似懂非懂,感觉这3个概念有重合,但又觉得不一样,能详细解释下吗?
”在表格数据模型中,关系只能在单个列上创建。引擎不支持建立在多个列上的关系“和”维度表包含用作唯一标识符的键列(一列或多列)以及描述性的列“这两句话是否矛盾,高老师
高老师,图片中的公式如果不作调整的话,会返回什么样的结果?为什么?
CountB = CALCULATE(COUNTROWS(‘Table’),’Table'[name]=”TV”),查函数大全解释中,第二个参数这里是布尔类型,那这个’Table'[name]=”TV”不是筛选条件吗?为什么文中说是替换为TV呢?
由于calculate计值流规则,外部上下文中的name列的所有值替换为“TV”,所以对于无论apple还是banana来说,calculate筛选后的值都是TV,TV属于electrical,所以apple、banana、TV,CountB都应该返回1,但是由于auto_exists,对于所有来自于table.name列的值,首先将值不等于TV的排除,所以在最终表里面不显示apple和banana。
但神奇的地方来了(ΩДΩ),默认开启了行小计和列小计,apple和banana的列小计显示的值均为1,TV的列小计为1,最终的行小计也为1。
可能学到后面就能明白了,先留个爪
大佬你好我有个问题想请教一下,我看了上面的星型模、雪花模都是一对多的形式,但是我们公司业务里面存在多对多的关系,例如一个量表,产品会把它同时放到几个分类里面去,导致最后join表结果是几个分类里面都出现同样的量表,这种情况上面的模型不合适应该怎么建立关系?
初学者,来学习
新书会包含付费内容吗
那个水果电视的例子有点不太懂:为什么那张表需要把apple, banana也归在electrical里面?它们不是属于fruit吗?
我觉得关于tableA,TableB这个例子,自动匹配的作用是导致列“Fruit”没有显示。
刚试了一下,CountB_New 和 CountB在最新版的Power BI中已经是相反的结果了,那看来就是优化过了,希望作者修订一下。
不太明白countB那个案例是哪里出现问题。理论上来说就不应该是1啊,反而countB_new对于我来说是一个错误的显示。还是说这个案例期望计算的场景不一样?
张飞那个二维表如何转换一维表呀
关于
Auto-Exists这部分内容有点迷糊,我自己实践了下,跟您这部分的描述有差异,难道是PB新版本跟以前的不一样吗?我试验的结果如下:
度量值:CountC和CountB_New是怎么写的。文章中未注明,
能否把文章中介绍的案例文件也分享一下。这样可以更好的操作。
反面案例的答案:这个度量值不太通用,如果有更多的销售月份 ,if的判断添加就要增加。
连续销售 =
var a1=SELECTEDVALUE(‘Sheet2′[一月销销量])
var a2=SELECTEDVALUE(‘Sheet2′[二月销量])
return SWITCH(HASONEFILTER(‘Sheet2′[客户编号]),a1=1 &&a2=1 ,2,a1=1 || a2=1,1)
是否能提供数据案例中的数据源呢
1.解决循环依赖问题
2.发生上下文转换时的可见行
以上2点看不懂,麻烦高老师能指点下。循环依赖平时遇到的比较少,但是上下文,一直都在迷茫中。经常会出现计算的结果不是想要的结果
DAX原理和高级原理什么时候更新呢?